

As expected on the outset of this series, Mediaflux’s Time Series capabilities and existing work in defence and geospatial mapping could offer some comparable ideas to autonomous vehicle industry. In the final part of this series, Arcitecta, provides insights on how this might play out to accelerate real world safety and performance testing.
Self-driving cars have been a popular part of our social imaginings for decades, is big data and IoT going to bring self-driving cars to reality?
From all reports, autonomous vehicles are producing a tremendous volume of data. Depending on what you read, this could be anywhere from 1TB per hour of driving up to 5TB.
So yes, it is clear that big data is going to play a major role in ensuring the future of self-driving cars, while the continued development of the IoT will form a necessary part of creating a world fit for autonomous transportation.
In Part 1 we touched briefly on how Time Series is used in autonomous vehicles, can you tell us a bit more about the types of data being ingested?
With the growing number of sensors in cars and the technology evolution towards higher resolutions of data types like video, radar and LiDAR; this myriad of technologies requires new data management approaches.
A lot of the data collected will be time series related and will come in a variety of different file formats. For example, the milliwave SAR (Synthetic Aperture Radar) or LiDAR data would probably come in as what is called an HDF5 file.
SAR or LiDAR files would also be used for detecting the road environment in front of the vehicle – looking for curvature in the road and to estimate the distance between obstacles. Recording the entire track of a test drive, that's really a lot of data.
Then there are small bits of data coming from global positioning systems (GPS), cameras collecting additional images that need to be processed, sensors determining speed and distances, vehicle-to-vehicle (V2V) and vehicle-to-infrastructure systems that collect additional surrounding information the list goes on.
And this may all sound excessive, but for testing purposes this makes sense; autonomous vehicles need big data to be able to see.
So because Mediaflux can ingest any sort of data, would it be correct to say that it creates a unification layer to coordinate the data from many devices?
Yes, from a time series perspective it would make sense to use Mediaflux as a unification system that could bring all sensor data into a single system.
One way this could play out is that you would have assets that represent the vehicle. Just like the simple fridge example in Part 1.
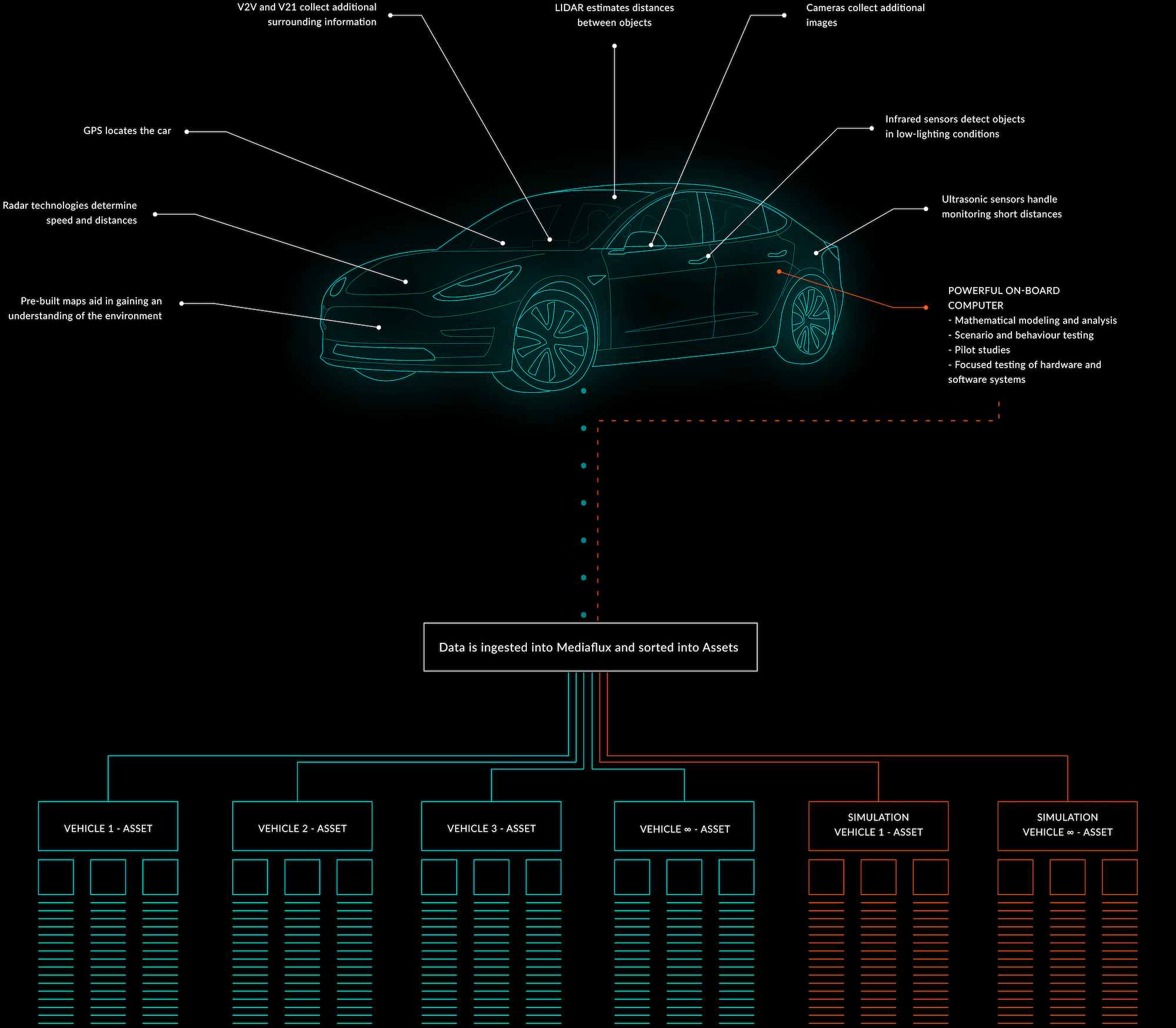
As in this diagram above, within each vehicle asset, you would then have additional assets that represent each test drive. Hanging off each of these we have all the time series for each of the test drives, which includes things like it's latitude and longitude overtime, the different tolerances of the engine and how it is working and so on. Each of these tests could also have associated with it the SAR and/or LiDAR data. Each of these data sources are all linked together as well as content on different assets.
So what we're doing in Mediaflux is linking all this data together in a way that a generic system could not do. A generic time series system could record the metrics from the accelerometers and the sensors on board the vehicle, but it wouldn't store the LiDAR or the SAR data files that come out of it at the end of the test.
On a generic Time Series, these additional files would be put into a file system somewhere. So what you would end up with another separate database system that has references to where things are in a file system. These would have to link those back together somehow in some big kludgy database. Mediaflux does all of that without special intervention.
Can you give us an example of how this might work in practice?
An example could be that each vehicle (assets) has metadata attached to show what Model it is. And each of the tests drives (sub-assets) of that vehicle would have metadata attached that identifies what iteration of the software was running on each test drive.
So we could say “show me everything where all of the vehicles of Model X were running tests where they were using version Z of the software that were driving within a particular area”. That's really fast filtering.
Next, you could say "show me all the LiDAR data we've got from each of these test drives over a certain location”. Try doing that on a generic system. What Mediaflux can do is look into all these files and filter by their geospatial coordinates. Mediaflux would build a geofence around that location and show me all the data for the queried vehicle type, software version and location; including the LiDAR data for any of those runs, bang straight away.
So were not talking about edge computing, we are talking about improving the analysis in the testing phase.
That's right. In the testing phase – which we still have many years and miles of – each manufacturer has the metrics of the vehicle and the LiDAR footage that they need. They can then bring together to replay and time sync it with the LiDAR to understand why the vehicle made the decisions it made.
For example, you know it saw a dog run across the road and the LiDAR showed a weird blob flying across the road. The software will then categorize that as a person or dog running across the road. The engineers would then want to look at the metrics to see how the vehicle behaved in that circumstance. Did it slow down? Or did it swerve? Mediaflux could store that information.
But, I think, the beauty of Mediaflux is better realised when you've got thousands of sources of these research vehicles on the road. If you've got just three sources, then a generic time series system would probably be faster in the offset because it's got less for it to do internally. Because when you're querying against that you're only really querying against that one thing.
Whereas with Mediaflux, it really comes into its own when you've got thousands and thousands of things that you're recording information about and slicing and dicing by the “thing” level, and then by the “thing” level where the time series contains XYZ. That's where Mediaflux comes into it own. I mean it's exponentially faster.
Attribution
Thumbnail/Cover Image — Image by Donald Giannatti on Unsplash.
