
Marc Loftus: I'd like to welcome you to the first in a series of three podcasts sponsored by Dell Technologies. In this first episode, titled The Era of Data Orchestration, I'm joined by two professionals with expertise in the space. First, I'd like to welcome Alex Timbs, head of Business Development and Alliances for Media and Entertainment at Dell Technologies. Welcome, Alex.
Alex Timbs: Thanks, Marc. Thanks so much for having me. I'm very much looking forward to today's discussion.
ML: Great to have you. Also joining us is Jason Lohrey, the CTO of Arcitecta, which has created its own comprehensive data management platform called MediaFlux. Mediaflux allows content producers to view and manage disparate data and ensure that it is captured and relayed to the right people. Jason, welcome.
Jason Lohrey: Thanks, Marc. It's a pleasure to be here. I am looking forward to the conversation.
ML: As I mentioned, episode one is titled The Era of Data Orchestration, and here we're looking to define some of the problems in the media and entertainment space. Who would like to start with identifying some of these challenges? Alex, how about you go first?
AT: There are several different factors influencing some of the challenges today. I suppose the most significant shift recently has been COVID-related and external pressures on businesses. Those pressures dictate that to get access to talent, you must have a considerable geo-distributed strategy in many of these pipelines. In addition to that, companies have had to seek out ways to reduce costs or look at reducing the cost of revenue. To achieve that, it often means outsourcing all moving production to parts of the world where there are either positives of tax outcomes or benefits to rebates, etc., to your business, or where the actual labour costs to achieve an outcome are a lot cheaper. So those forces, I think, combined with the general innovation that occurs in media and entertainment in particular, because it's constantly changing, has led to a significant amount of transformation and pressure on changes to how we move, consume, and measure data in particular.
JL: The world's also shrinking, though, isn't it? It's easier to get to people. People work across time zones; now we've got 'follow the sun' production pipelines. And we need to get to the best quality talent when we want to produce the highest quality outcomes. So, I think anything that enables us to bring teams of people together, no matter where they're living or working, is an advantage. And that's what we're looking at with the orchestration of data.
ML: So much of that we've heard leading up to and even before COVID. We are looking for talent wherever the talent is available and finding ways to benefit from the incentives of working in other places where economics are driving it. At the same time, file sizes have increased with all the digital acquisition cameras and formats, and more recently, COVID is moving more people to remote workflow. It seems like we were heading toward more distributed teams, but it's all come together more so in the past two years.
JL: It was going in that direction. But COVID has amplified that and made people realise that you can work in a disconnected and disparate way. It's a forcing function if you like, but we would have been heading that way anyway. The other thing is that the complexity and the amount of data we're managing for production are increasing. As we get to higher and higher fidelity content, the quality and the number of assets we need to manage are growing. We're typically in the orders of hundreds of millions of assets, but we'll get to the range where we need to manage billions of things. The size of things is increasing. My background was with Kodak and Cineon in the early nineties working at 4K resolutions. At that time, a lot of people worked at 2K. Now we're in the ranges of eight, 12, 16 and beyond. Those files get bigger, and as your workflows use larger amounts of data, it gets harder to move those around the globe. So we need to focus on how we move. We can't beat the laws of physics. It takes a certain amount of time to transmit light around the globe. But we can do things to accelerate the transmission, using parallelism, etc. but we need to bring people together that are separated by large distances, and we need to transmit larger and larger files and increasingly larger numbers of these. And we need to keep track of where everything is.
ML: Jason, you've authored an article that coincides with this discussion, and I'm going to share the link in the details for this podcast. But, essentially, you're saying that the data has grown to such a large amount that we, humans, cannot manage it efficiently.
JL: I don't know about you, Marc, but I struggle to keep track of a few hundred things, let alone millions and billions of things. And we're heading into that era where there are so many bits and pieces for humans to keep track of; it's impossible without automation. And the human becomes a limiting factor in our ability to increase the fidelity of production, visual effects or others. So we need systems to help us automate those processes as much as possible.
ML: How have post pipelines evolved from how they worked in the past, even before COVID? Because collaboration isn't a new concept and what we're seeing now. Jason, do you want to start with that?
JL: It used to be the case that people used to collaborate, but it was more challenging. We used to be in a world where we ship drives around, physical disk drives from one place to the other. We can no longer sustain those processes, given the time it takes to do that and the scales we are operating at. We need to be much more collected, connected, and immediate these days.
ML: Alex, how about you? You spent time at Animal Logic, a high-end studio, before joining Dell three years ago. What have you experienced?
AT: Following on from what Jason said, there's been a shift from the traditional linear pipeline where it was one department to the next. It was like a manufacturing line. So someone had to finish something, they passed that widget over to the following department or the next person, and then they do a process on it, and they'd have an output, so on and so on. That's gone.
Businesses can't sustain that linear process. It's not efficient enough to survive. So really, the focus now is on adding metadata-driven automation. It's about delivering quality creative output on time and within budget. And to achieve that at scale, you have to automate where possible. And as Jason has said, it's happening across hundreds of shots, hundreds of crew and thousands, if not millions of versions, all working towards this common output.
It just can't happen fast enough in the modern day. So you have to make this a very automated approach. To give you an example, consider the radical growth in size and scope of datasets associated with content, as I've experienced. When I started in M&E, the show that I was working on had its final assets and all of the dependencies for those final assets sitting on disk at roughly 64 terabytes. If you fast forward to one of the last shows I worked on before moving across to Dell Technologies, which was only three years ago, and you looked at the final images and the dependencies, they were four petabytes. Four petabytes. That's a significant change. That's a lot more storage. And to give you additional context, at the same time, budgets shrunk to about a third of what they were before. So what does it mean?
It means that M&E businesses must focus on metadata-driven automation to use their data efficiently. And that includes things like deprecating unused assets. The only way you can do that is by using tools that allow you to answer questions rapidly and automate your pipeline because it's humanly impenetrable at this scale. Fundamentally, media and entertainment, particularly animation and visual effects, success is based on how low the friction is between human interactions. So part of that is collaboration storage because you've got all these different departments, story animation, compositing, design, lighting, etc., each with tens of people, sometimes hundreds of people in them. They're all collaborating, working towards a shared goal: to tell this unique story and make these amazing pictures. So they all centre around this pool of data, with storytelling at the core. So reducing the amount of friction between those individuals is so critical.
Improving the quality and efficiency of these pipelines is probably less about new ideas and more about the dynamics and the connections and reducing the friction between them because the human element within these pipelines makes every single pipeline distinct. So reducing friction supports creativity and allows for a better outcome. To achieve that, businesses typically have had this single silo of storage and made that data as fast and available as possible for all these individuals, particularly in non-linear pipelines. This is where every department collaborates; every output from a department is an input for another. We see a lot more of that in universal scene description (USD) pipelines. But now, because of the geo-distributed nature of production, we've had to move from having this single silo of storage behind a firewall to a scenario where we bring the data to the people. That data could be small hubs or another business that's a satellite office. It could be a single freelancer that you're only giving access to for a week, and you need to be able to deliver the right data or assets to them to work on in a timely fashion in their home, on a machine that you may not even manage or own.
There's a whole cyber story here that we may get into in further conversation. But overall, the paradigm has changed radically, yet the drivers are still the same. It's about reducing the friction between human collaboration. If you reduce the friction, you will get a better creative outcome.
ML: The security needs are one aspect we're going to look at in our next episode, different levels of permissions and approvals. But without going into the solutions now, can we first look at how Dell and Arcitecta became aware of each other and how they started working together?
AT: I've been aware of Arcitecta for many years while working in the studio. The reason for that awareness was that in these businesses I've alluded to, the biggest challenge is typically storage and rendering or compute resources. Those are the two most significant things the company consumes and needs in creation. Businesses are always looking at ways to do things better, adding automation and managing their limited resources more efficiently to get better-optimised output. Many times I ran into Jason on that search for doing things better. I've been aware of Arcitecta by touching on their business, while looking for better solutions, and better ways of doing things. But it wasn't until I started at Dell Technologies that we started running into each other a lot more. Part of that, I think, was driven by the fact that they have a solution or a capability of bringing a solution to the table that fundamentally meets a lot of these challenges head-on. They have a tremendous amount of flexibility in their Mediaflux product. Based on this experience, I naturally gravitated quite heavily towards them because it ticks so many boxes for me, still sitting in the customer's seat. That's how I view the world most of the time. How would this improve my business? How would this improve a customer's pipeline? And it just resonated for me. I suppose that helped deepen the relationship since being at Dell. Jason do you want to add any more colour to that?
JL: For a long time, we have had joint customers where we drive Dell storage phenomenally well. We've got unique capabilities that talk very well with formerly Isilon now PowerScale. The other thing we're doing is lifting the level of the conversation. I think many people like to talk about their data problems, not their storage or hardware problem, so that's the advantage of this relationship. It lifts that conversation. We need to sit on hardware, preferably excellent hardware. And so, as we raise that conversation, partnering up with Dell to provide the infrastructure with us is a sort of a perfect combination.
ML: One of the keys that I know that we want to discuss was syncing data and how it's something that we've been aware of now but has a more critical role. Is that something you want to talk about, Jason?
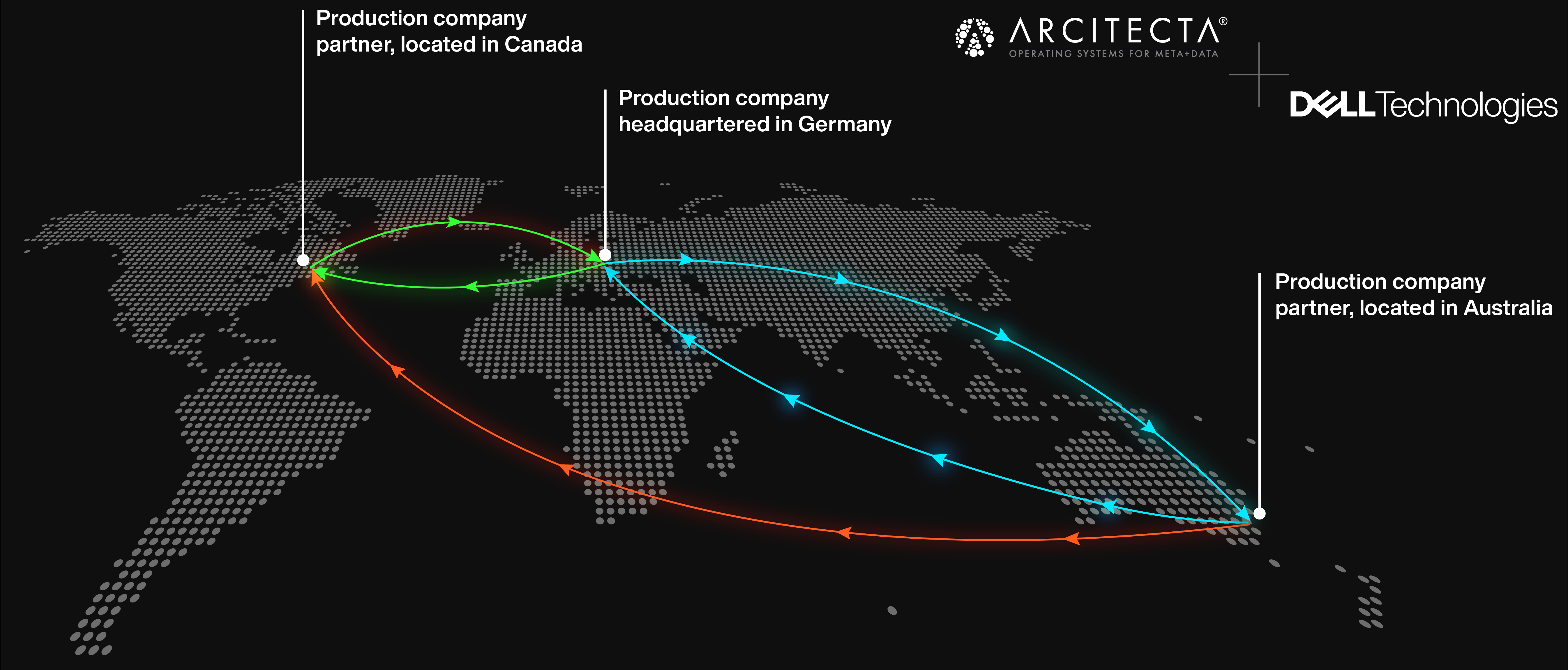
JL: In the world of distributed content production, obviously you need to transmit data over larger distances. The larger the distance, the longer it takes the light to travel, and the longer it takes, the greater the latency between those endpoints. For example, I'm in Melbourne, Australia, and the time it takes the light to travel to the west coast of the US is around 177 milliseconds. That makes it hard to get things moving at speed. So we need better systems for transmitting at speed. But it's not just about speed. Those systems need to be integrated with the data management fabric to ensure that we get just the right data at the right time to the right endpoint and know what's there. Requirements for governing, what data goes where means we also need to inspect those transmissions to ensure we're not sending things that we shouldn't to somewhere else. So the transmission from point A to B should be part of an overall data management fabric. And those are things that Mediaflux addresses inherently.
ML: Rarely is it just two facilities working back and forth. There are often many facilities in different time zones, so it's not the management of point-to-point; it's a point-to-many relationship.
JL: Point to many, and many to many. And the shape of that can change over time. You might be outsourcing work to another location, and they might outsource to another, creating bidirectional cooperation, which all need workflow orchestration. It becomes a workforce management problem as much as it is about getting the data to those people when required. Additionally, if work is completed in different time zones, knowing what somebody has completed the night before so that collaborators can pick it up at the beginning of their day that's a workflow problem. And that's something people find pretty challenging to deal with. You want to minimise the amount of crossover or overlap so production can follow the sun as smoothly as possible.
ML: In our next episode, we'll look at practices and solutions to help content creators deal with these challenges. Alex and Jason, I hope you'll both come back and share your insight into how Dell and Arcitecta can help.
JL: Looking forward to it, Marc.
AT: Likewise.
ML: I want to thank our listeners for tuning in and encourage you to stay tuned for Episode two. I'd also direct them to postmagazine.com, where they can read Jason's article on the era of data orchestration. Thanks again.
